최근 서비스 안정성 매우 중요합니다. 카카오 장애, 배민 주문 장애
기업의 서비스 만족도, 신뢰도에 가장 악영향을 끼치는 요소중에 하나입니다.
허나 최근 많은 서비스들이 MSA로 전환하면서 Kubernate의 도입은 빠르게 전파되고 있습니다.
하지만 우리가 매일 사용하고 있는 쿠버네티스....... 배포하는 순간에도 100% 서비스 안정성을 보장하고 있을까요?
달리고 있는 자동차에 바퀴를 빼는 일은 매우 위험한 일입니다. 하지만 우리의 서비스는 멈출 수 없고
새로운 업데이트된 내용들은 반영 해야 합니다. 그럼 어떻게 진행 해야 할까요?
이번 시간을 통해 무중단 배포에 대해 한번 알아 보시면 좋겠습니다.

배포전략에는 여러가지가 존재 합니다. 상위 Layer에서의 Green/Blue, A/B Test,
하지만 오늘은 Application Service Layer에서의 배포전략에 대한 문제를 다루고자 합니다.
Pod Application 배포를 할때 서비스 중단을 막기 위해 Rolling Update옵션을 제공합니다.
Application 배포에 Rolling Update를 적용하며 가졌던 시행착오와
추가적인 옵션으로 0% 실패율을 만들기 위해 거쳤던 시행착오를 설명 드리겠습니다.
To Do
Rolling Update를 통해 이미지를 업데이트(배포) 할때, Traffic을 온전히 소화 할 수 있는지 확인하여,
안정적으로 서비스 가능한지 확인하고자 합니다.
- 이미지를 새롭게 배포할때(Rolling Update) K6를 통해 Traffic생성 후 실패율 확인
- 최적의 배포 옵션을 위해 Rolling Update에 Probe 설정 및 적용
- 테스트 및 확인
Prerequisite
- Rolling update (배포전략)
- Probe (Health Check)
- ALB (Application Load Balancer)
요약
Abstract을 서두에 먼저 적어 놓았습니다. 빠른 결론을 확인하시고 내려 가시면서,
해결과정의 History를 하나씩 확인해 보시면 이해 하시기 더욱 좋을 듯 합니다 :)
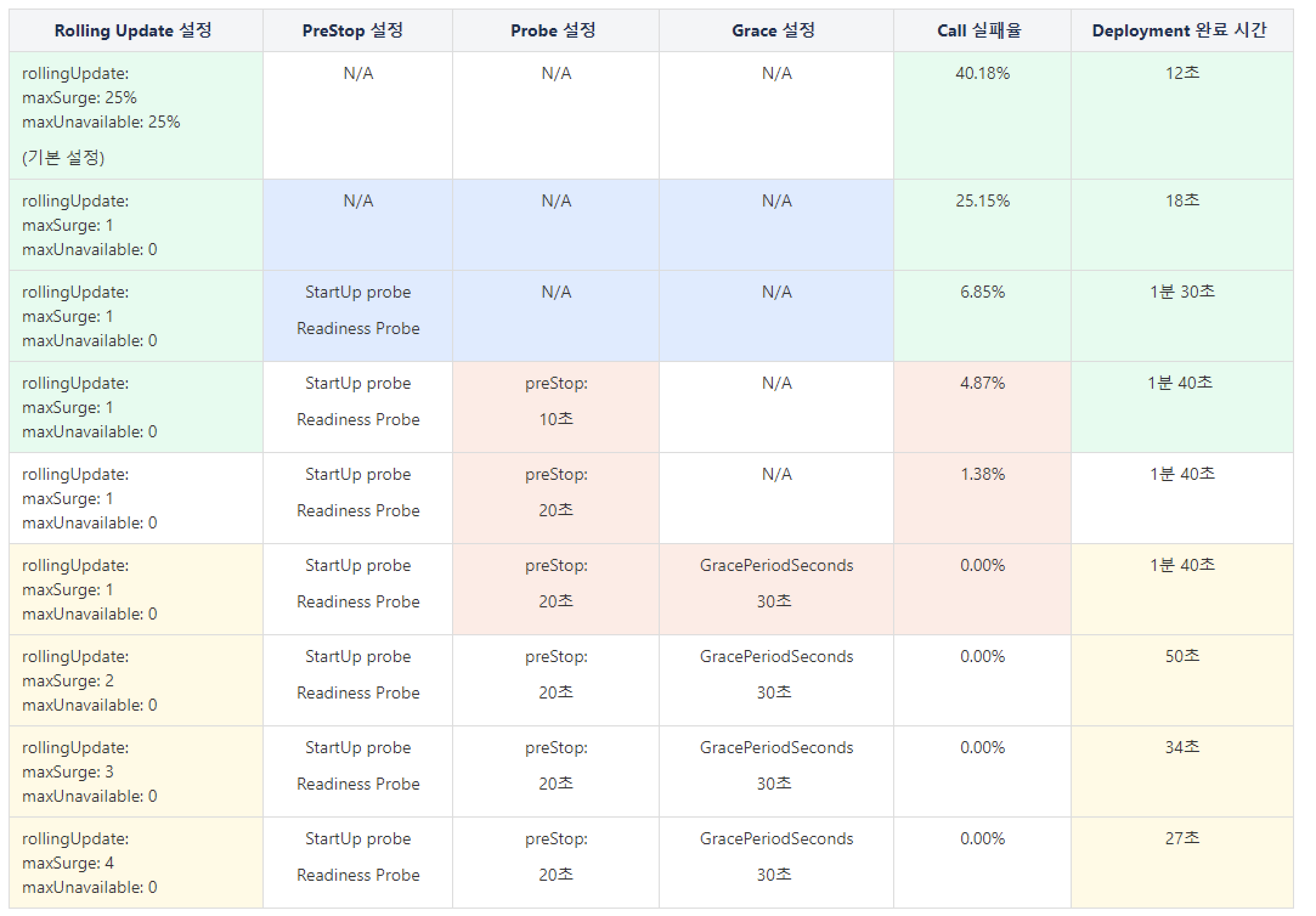
| Rolling update으로 배포시에 다양한 옵션들이 존재 합니다. Rolling update 하위에 MaxSurge는 새로운 바퀴를 몇개나 한번에 새로 갈아끼울지를 뜻합니다. 서버 가용성이 좋다면, 한번에 여러개의 파드를 생성하여 보다 빠른 시간에 배포를 마칠 수 있을 것입니다. 하지만 많은 CPU와 메모리 사용을 어쩔 수 없는 Trade Off라고 생각됩니다. 따라서 프로젝트 현황에 맞게 잘 판단 하시면 될 듯 합니다. 다음으로 MaxUnavailable은 서비스 중에 Pod중 몇개나 서비스가 Unavailable해도 되는지를 뜻합니다. 물론 무중단 배포를 위해서는 0이 되어야 겠지요 하지만 서버 자원 가용성이 좋지 못한 경우라면, 0 이상으로 허용하여, 새벽 시간대에 배포 한다거나 하는 식의 플랜 B로 가져 가야 할 것입니다. 아래에서 자세한 설명이 있지만 quick하게 Probe에는 3가지 옵션에 대한 목적성에 대해 설명 드리겠습니다.. (StartUp Probe, Liveness Probe, Readiness Probe) Application 에서는 Readiness Probe와 StartUp probe를 사용하였고, Liveness는 Service가 살아 있는지만 체크하는 기능이기에 사용하지 않았습니다. 내부적인 설명을 조금 드리자면, Startup Probe(선결 조건)가 Application이 살아 있는지 1차적으로 Health체크를 하고 살아 있다고 판단되면,(Startup Probe가 실패 하면 Readiness는 작동 하지 않습니다) Readiness Probe를 통해 호출 해야 하는 path에 여러번 성공 케이스가 중첩되면 Traffic을 받을 준비가 되었다고 판단하여 Traffic을 흘려 보낼 수 있게 Endpoint List에 추가 하게 됩니다. 해당 두 옵션을 통해 ALB에서 Group In 되는 시점에 Backend가 준비가 되었는지 Health체크를 통해 Backend가 준비되지 못하여 Fail되는 상황을 방지 할 수 있었습니다. 다음으로 PreStop을 통해 ALB에서 Group out 되기전 받았던 Traffic에 대한 처리가 가능하였습니다. Group Out 되기전 들어오는 요청들이 Kubernate에 의해 Application 파드가 수행중에 배포작업으로 인해 중지 된다면 요청 받았던 Traffic은 Terminate된 상황에 의해 모두 Fail처리가 될 것입니다. 하지만 PreStop을 통해 ALB에게 Group out되는 시간적 여유를 주고, Old Pod는 그 동안 받았던 요청들을 모두 처리하고 Terminate 됩니다. Application이 15초 안으로는 모든 처리를 소화 하도록 Timeout 설정이 되어 있고, 따라서 Padding 값을 더하여 20초로 설정하였습니다. 만약 20초에 해결 되지 못하더라도 Grace옵션을 통해 10초 정도 더 여유 시간을 주기에 ALB에서 Group out되는 시간적인 여유로는 충분하다고 판단이 되었고 여러 측정을 통해 Fail case 없이 가장 안정적으로 배포 가능한 옵션의 시간 값을 확인 하였습니다. |
옵션 반영에 따른 측정 결과
- 배포 완료까지 Call을 Graceful Stop방식으로 Traffic을 요청
- 처음 10초: vUser 0 ➔ 1,000 다음 배포 완료 10초 전까지 : vUser 1,000 유지 마지막 10초: vUser 1,000 ➔ 0
- 동시 접속자 수 1000명
- 최적의 환경에서 초당 (3939.761705/s ~ 4530.300122/s) 처리
옵션 적용에 따른 기대효과 설명

Rolling Update시 실패율 확인
시나리오: 새로운 이미지를 새롭게 배포할때 트레픽을 가하여 서비스 실패 확률을 측정 환다.
환경: Replica: 8
테스트 스펙
Time duration: 배포 완료 까지
Duplicate users: 1000 virtual users
테스트 방법 (k6 부하 테스트 툴 사용)
| # Admin EKS에서 실행 $kubectl apply -f deployment.yaml # 로컬에서 실행 $ ./test 1000 (요청하고 싶은 동시 사용자 수) |
test.sh (local)
#~/bin/bash
k6 run -u 0 -s 10s:1000 -s $1s:1000 -s 10s:0 --out json=result.json --summary-trend-stats="med,p(95),p(99.9)" script.jsscript.js (local)
import http from "k6/http";
export default function() {
let response = http.get("http://localhost:8080/test");
};Rolling Update 적용 Test result
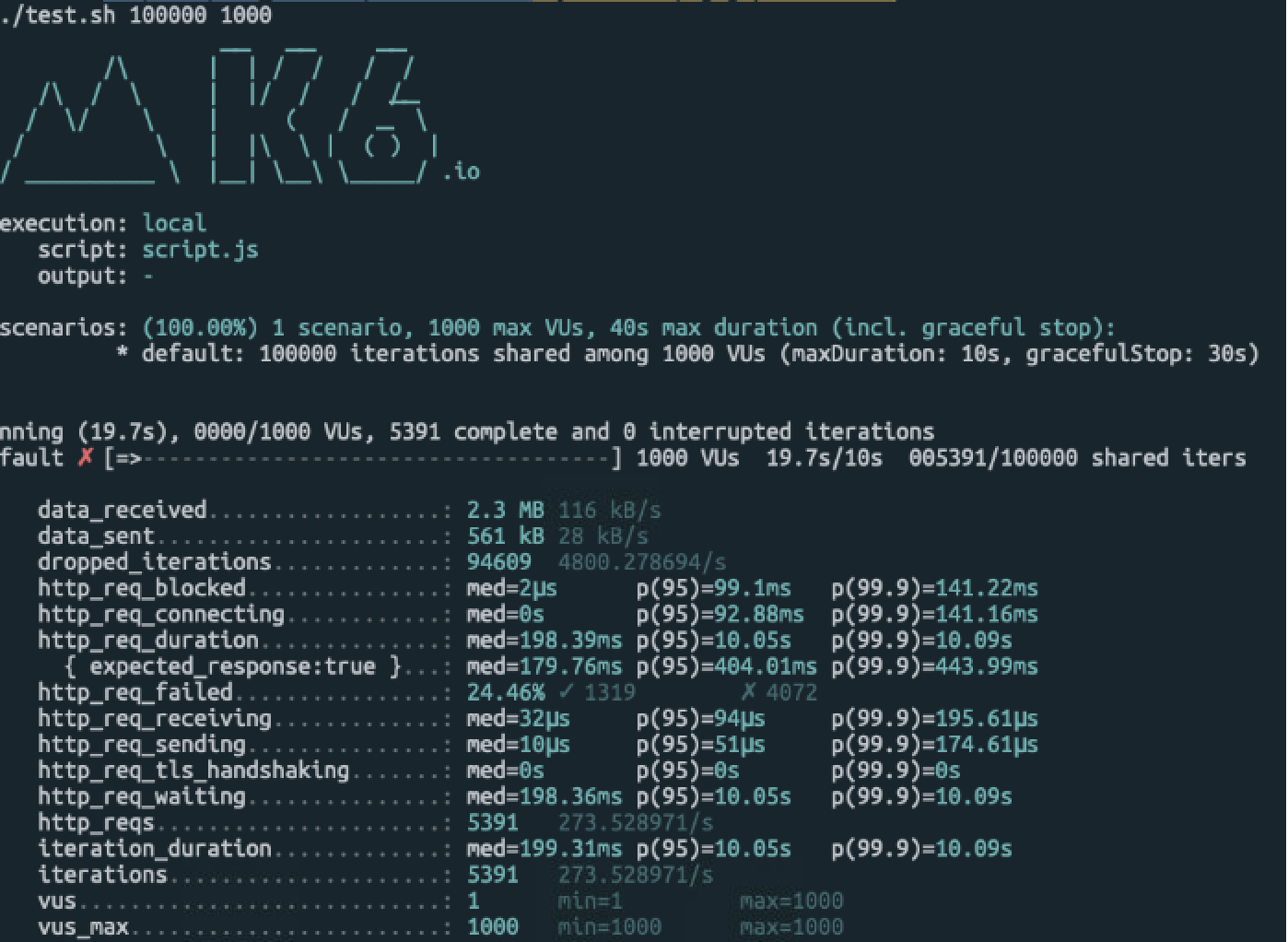
- 10000 calls / 1000 users
- 실패 확률: 24.46%, 23.55%
Container Probe?

개념
- Probe 는 Kubelet을 이용하여 주기 적으로 진단을 수행한다.
- Kubelet은 컨테이너 안에서 코드를 실행하거나 네트웍 요청을 수행한다.
Probe 종류
- LivenessProbe
- 컨테이너가 동작 중인지 여부를 나타낸다. 만약 활성 프로브(liveness probe)에 실패한다면, kubelet은 컨테이너를 죽이고,
- 해당 컨테이너는 재시작 정책의 대상이 된다. 만약 컨테이너가 활성 프로브를 제공하지 않는 경우, 기본 상태는 Success 이다.
- ReadinessProbe
- 컨테이너가 요청을 처리할 준비가 되었는지 여부를 나타낸다.
- 만약 준비성 프로브(readiness probe)가 실패한다면, 엔드포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거한다.
- 준비성 프로브의 초기 지연 이전의 기본 상태는 Failure 이다. 만약 컨테이너가 준비성 프로브를 지원하지 않는다면, 기본 상태는 Success 이다.
- StartupProbe
- 컨테이너 내의 애플리케이션이 시작되었는지를 나타낸다. 스타트업 프로브(startup probe)가 주어진 경우,성공할 때까지 다른 나머지 프로브는 활성화되지 않는다.
- 만약 스타트업 프로브가 실패하면, kubelet이 컨테이너를 죽이고,컨테이너는 재시작 정책에 따라 처리된다. 컨테이너에 스타트업 프로브가 없는 경우, 기본 상태는 Success 이다.
Check logic
- exec
- 컨테이너 안에서 지정된 명령어를 실행한다. 명령어가 상태코드 0으로 수행이 끝나면 성공으로 간주함
- gRPC
- gRPC를 통해 원격 프로시져 호출을 수행한다. (기능을 활성화 해야 사용가능)
- httpGet
- 지정한 포트 및 경로에서 Http Get 요청을 수행한다. return 값이 200 이상 400 미만이면 성공
- tcpSocket
- 지정된 포트에서 컨테이너 IP주소에 대해 TCP 검사를 수행한다.포트가 활성화 되어 있으면 진단이 성공적이라고 간주한다.
Probe 적용

적용 사유
- Readiness Probe를 사용하는 이유는 많은 트래픽에 노출 되어 있는 상황에서, 순차적인 배포를 통해 서비스를 안정적으로 제공하면서 배포를 진행 할 수 있기 때문입니다.
- StartUp probe는 Readiness Probe 가 작동하기전에 Backend가 살아 있는지 확인하고 Readiness를 통해 트레픽을 감당할 수 있는 상태인지 확인 합니다.
환경 설정
- startupProbe 추가
- readinessProbe 추가
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
selector:
matchLabels:
app: application
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
replicas: 8
spec:
containers:
- name: application
image: ecr_img_url
imagePullPolicy: Always
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /test
port: 8080
initialDelaySeconds: 0
failureThreshold: 5
successThreshold: 3
periodSeconds: 1
startupProbe:
httpGet:
path: /__health
port: 8080
initialDelaySeconds: 0
failureThreshold: 3
successThreshold: 1
periodSeconds: 10
volumeMounts:
- name: config
mountPath: /etc/app/
terminationGracePeriodSeconds: 60
nodeSelector:
nodegroup: ng-test-dev적용 결과
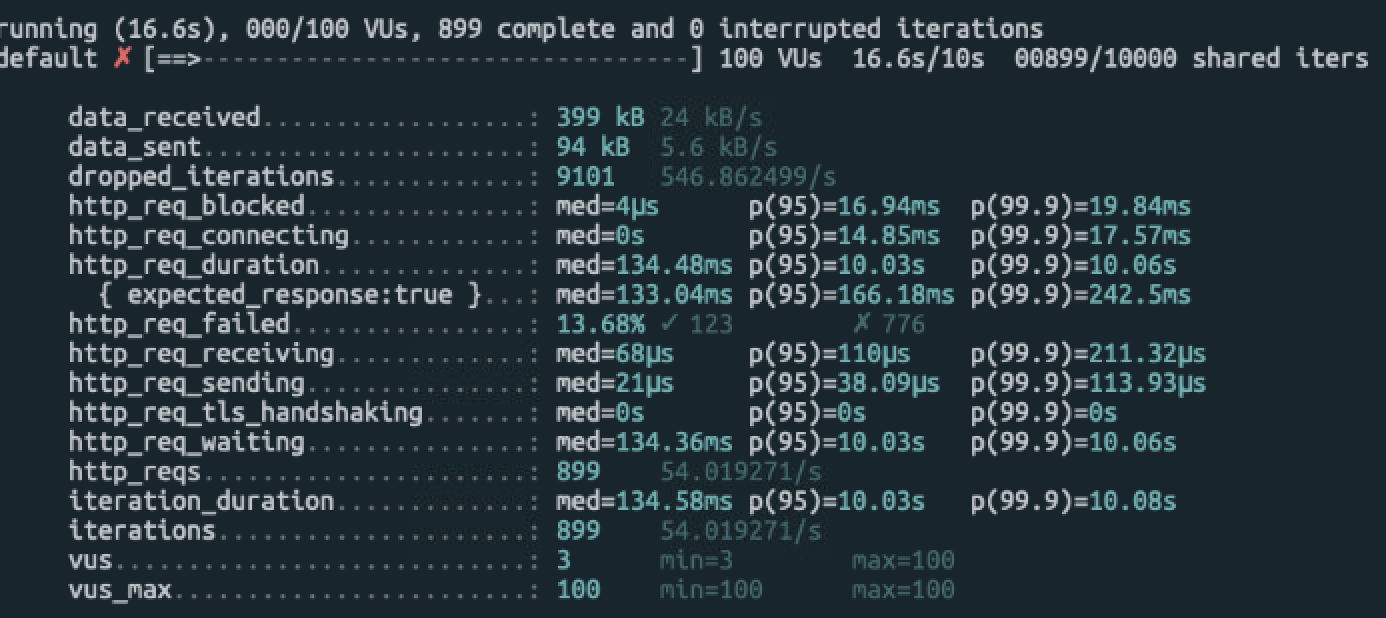
- 실패 확률: 21.6%, 15, 33% (적용 전) → 13.68%, 8.50%(적용 후)
문제 확인
Drill Down ⛏
- 일정한 비율로 (7~8% 언저리)로 계속 Fail이 발생하였고, 그 정도 Size는 1개의 Pod가 소화할 만한 Traffic 정도라고 생각이 들었습니다.
- 첫번째로 의심할 수 있을 만한 상황은 Pod가 내려지고(Draining) Terminate되는 순간에 처리 되어야 하는 Traffic이 유실 되었기에 Pod가 가장 의심이 되었습니다. (Life cycle)
- 두번째로 의심할 수 있을 만한 곳은 ALB이였습니다. 사실 파드에게 요청을 전달해주는 곳이기 때문입니다. (ALB 빼고 연관된 다른 부분이 없었습니다)

유사한 이슈를 찾아본 결과 Pod가 문제가 아니라 ALB Ingress Controler 가 문제라는 것을 발견 하였습니다.

이슈는 2가지 경우에서 발생됩니다.
|
- 한줄 결론: PreStop을 통해 ALB에게 시간의 여유를 주자! Probe설정도 중요하다 !
문제 해결
Approach
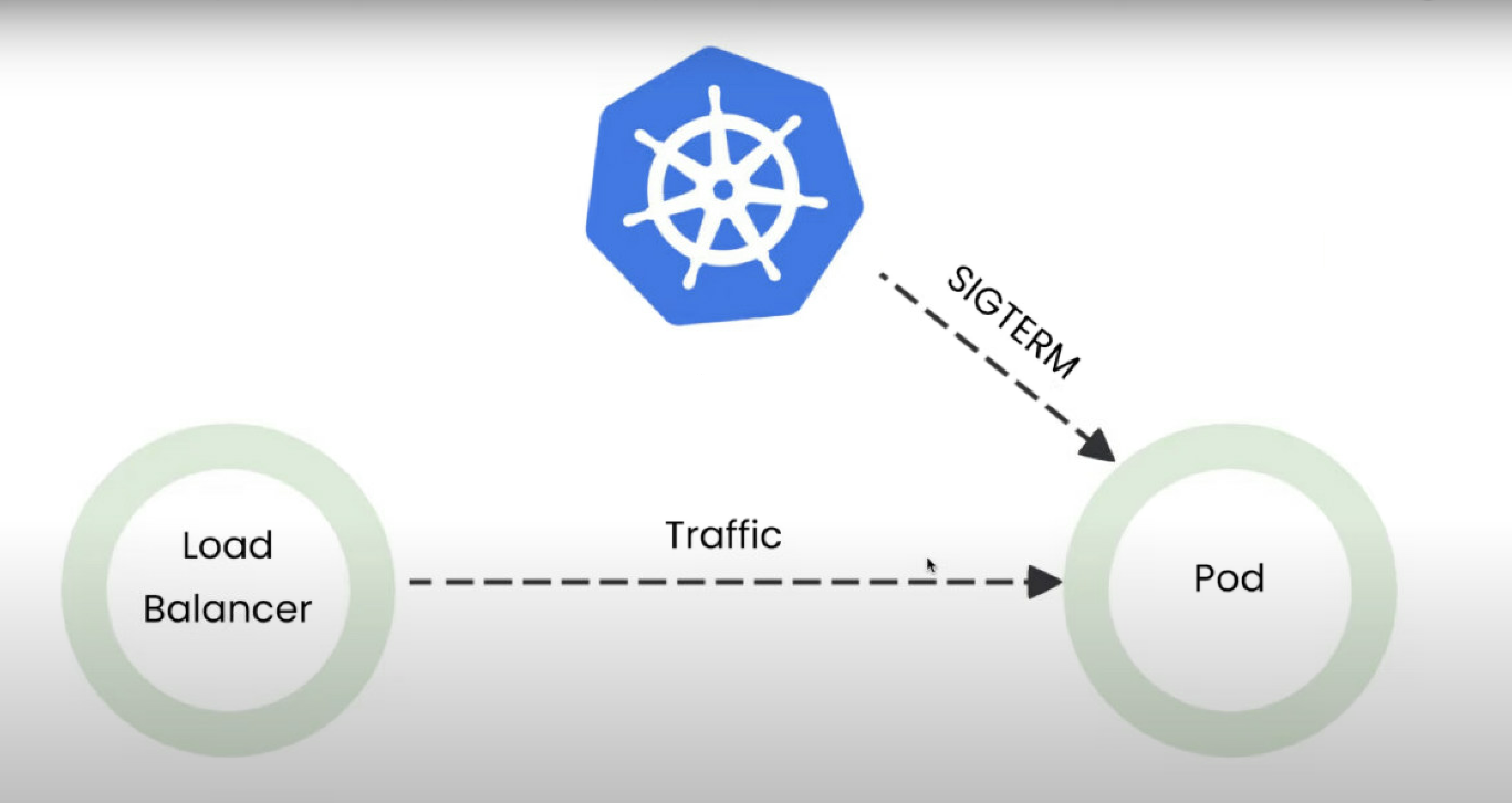


Readiness와 StartupProbe를 적용했지만 여전히 Corner 케이스가 발생하여 Fail이 발생하고 있고, 추측하건데 1개의 파드 Size만큼 Fail이 발생하는 것으로 보아 Terminate 되는 시점에 이미 받았던(Endpoint List에서 제거 되기 이전 시점에 받은) Traffic들을 모두 처리 하지 못하고 Fail 처리 되었습니다. 찰나의 순간에 500 에러를 마주할 수도 있겠지만, 순수하게 무중단 배포(서비스)를 완성하기 위해서는 추가 작업이 더 필요할 듯 합니다
문제 해결 방법
- strategy 설정 변경
- maxSurge를 1로 명시하여, 1개의 추가 파드가 생성되고(새로운 이미지), 삭제 될 수 있도록 변경하였습니다.
- Maxunvailable 은 0으로 변경하여 Replica 8의 옵션을 계속 유지할 수 있도록 하였습니다.
- preStop 설정 추가
- Terminate되기 전에 시간을 주어 요청을 소화 할 수 있도록 변경 하였습니다.
- terminationGracePeriodSeconds 설정 추가
- preStop 설정시간 내에 요청을 모두 처리 하지 못하는 경우 Graceful 옵션을 통해 조금 더 여유시간을 확보하여 요청을 모두 처리 할 수 있게 하였습니다.
- 최종 resource.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
selector:
matchLabels:
app: application
strategy:
rollingUpdate:
maxSurge: 2
maxUnavailable: 0
replicas: 8
spec:
containers:
- name: application
image: ecr_img_url
imagePullPolicy: Always
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /test
port: 8080
initialDelaySeconds: 0
failureThreshold: 5
successThreshold: 3
periodSeconds: 1
startupProbe:
httpGet:
path: /__health
port: 8080
initialDelaySeconds: 0
failureThreshold: 3
successThreshold: 1
periodSeconds: 10
lifecycle:
preStop:
exec:
command: ["sleep", "20"]
volumeMounts:
- name: config
mountPath: /etc/app/
terminationGracePeriodSeconds: 30
nodeSelector:
nodegroup: ng-test-dev최종 결과
- 실패 확률: 13.68%, 8.50%(Probe만 적용) → 0% (최종 옵션 적용 완료)
- 무중단 배포에 성공! 실패율 0% 달성.

참고 (Referance)
- K6 사용방법
- (공식) 파드 라이프 싸이클 (아래의 내용을 읽기전에 미리 읽어보면 다음을 이해 하는데 도움이 됩니다)
- (공식) Liveness, Readiness and Startup Probes
- Pod 생성시 probe 설정하기
- Zero downtime deployment(RollingUpdate) when using AWS Load Balancer Controller on Amazon EKS
'개발' 카테고리의 다른 글
| Fluent-bit를 통한 Kubernetes 로그환경 구축 (0) | 2023.04.03 |
|---|---|
| ECR Multi Architecture(amd64/arm64) 이미지 저장하기 (0) | 2023.03.23 |
| MSA 성능 향상을 위한 gRPC 이해 및 적용 (0) | 2022.11.18 |
| OIDC Auth2.0 Hydra (0) | 2022.11.09 |
| Kubernetes Bare Metal Server 구축 (CLI-O, Calico) (0) | 2022.10.18 |